A year and two and a half months since his Time magazine doomer article.
No shut downs of large AI training - in fact only expanded. No ceiling on compute power. No multinational agreements to regulate GPU clusters or first strike rogue datacenters.
Just another note in a panic that accomplished nothing.
why would rationalists do something difficult and scary in real life, when they could be wanking each other off with crank fanfiction and buying castles manor houses for the benefit of the future
considering that the more extemist faction is probably homeschooled, i don’t expect that any of them has ochem skills good enough to not die in mysterious fire when cooking device like this
It’s also a bunch of brainfarting drivel that could be summarized:
Before we accidentally make an AI capable of posing existential risk to human being safety, perhaps we should find out how to build effective safety measures first.
Or
Read Asimov’s I, Robot. Then note that in our reality, we’ve not yet invented the Three Laws of Robotics.
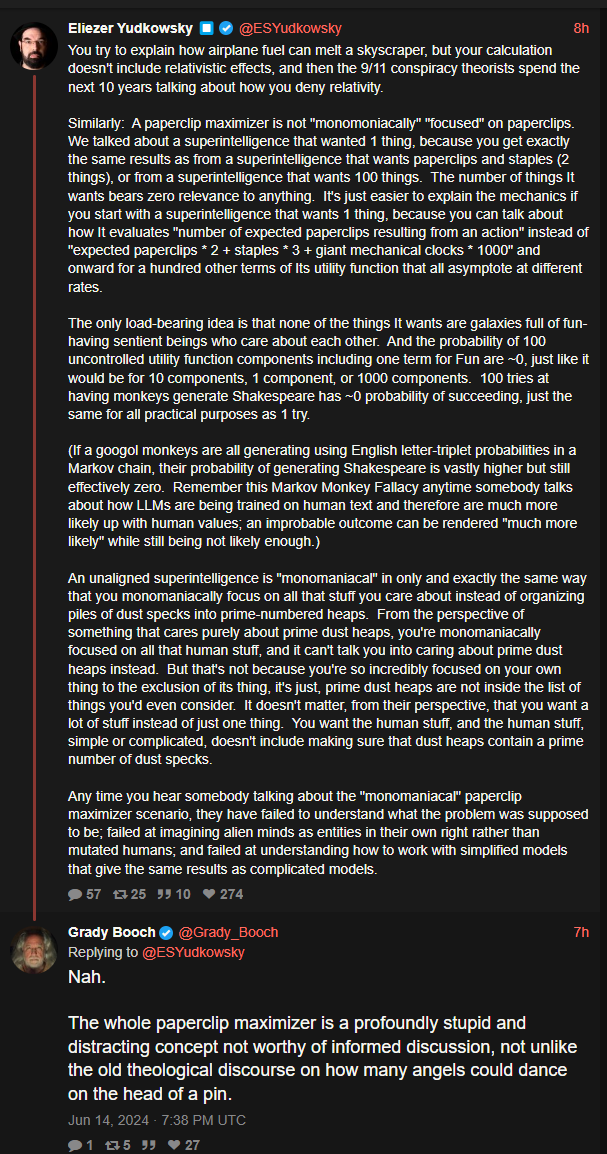
That’s a summary of his thinking overall but not at all what he wrote in the post. What he wrote in the post is that people assume that his theory depends on an assumption (monomaniacal AIs) but he’s saying that actually, his assumptions don’t rest on that at all. I don’t think he’s shown his work adequately, however, despite going on and on and fucking on.
Before we accidentally make an AI capable of posing existential risk to human being safety, perhaps we should find out how to build effective safety measures first.
You make his position sound way more measured and responsible than it is.
His ‘effective safety measures’ are something like A) solve ethics B) hardcode the result into every AI, I.e. garbage philosophy meets garbage sci-fi.
yeah it’s been absolutely hilarious to watch this play out in LLM space. so many prompt configurations and model deployments with so very many string-based rule inputs, meant to be configuring inviolable behaviour, that still get egregiously broken
and afaict none of the dipshits have really seemed to internalise that just maybe their approach isn’t working
Before we accidentally make an AI capable of posing existential risk to human being safety
It’s cool to know that this isn’t a real concern and therefore in a clear vantage of how all the downstream anxiety is really a piranha pool of grifts for venture bucks and ad clicks.


A year and two and a half months since his Time magazine doomer article.
No shut downs of large AI training - in fact only expanded. No ceiling on compute power. No multinational agreements to regulate GPU clusters or first strike rogue datacenters.
Just another note in a panic that accomplished nothing.
At least the lack of Rationalist suicide bombers running at data centers and shouting ‘Dust specks!’ is encouraging.
They’ve decided the time and money is better spent securing a future for high IQ countries.
why would rationalists do something difficult and scary in real life, when they could be wanking each other off with crank fanfiction and buying
castlesmanor houses for the benefit of the futureconsidering that the more extemist faction is probably homeschooled, i don’t expect that any of them has ochem skills good enough to not die in mysterious fire when cooking device like this
so many stupid ways to die, you wouldn’t believe
@Shitgenstein1 @sneerclub
Might have got him some large cash donations.
tap a well dry as ye may, I guess
ETH donations
It’s also a bunch of brainfarting drivel that could be summarized:
Before we accidentally make an AI capable of posing existential risk to human being safety, perhaps we should find out how to build effective safety measures first.
Or
Read Asimov’s I, Robot. Then note that in our reality, we’ve not yet invented the Three Laws of Robotics.
That’s a summary of his thinking overall but not at all what he wrote in the post. What he wrote in the post is that people assume that his theory depends on an assumption (monomaniacal AIs) but he’s saying that actually, his assumptions don’t rest on that at all. I don’t think he’s shown his work adequately, however, despite going on and on and fucking on.
If yud just got to the point, people would realise he didn’t have anything worth saying.
It’s all about trying to look smart without having any actual insights to convey. No wonder he’s terrified of being replaced by LLMs.
LLMs are already more coherent and capable of articulating and arguing a concrete point.
You make his position sound way more measured and responsible than it is.
His ‘effective safety measures’ are something like A) solve ethics B) hardcode the result into every AI, I.e. garbage philosophy meets garbage sci-fi.
This guy is going to be very upset when he realizes that there is no absolute morality.
A good chunk of philosophers do believe there are moral facts, but this is less useful for these purposes than one would think
yeah it’s been absolutely hilarious to watch this play out in LLM space. so many prompt configurations and model deployments with so very many string-based rule inputs, meant to be configuring inviolable behaviour, that still get egregiously broken
and afaict none of the dipshits have really seemed to internalise that just maybe their approach isn’t working
It’s cool to know that this isn’t a real concern and therefore in a clear vantage of how all the downstream anxiety is really a piranha pool of grifts for venture bucks and ad clicks.