

I definitely feel the pain when it comes to worthless results nowadays. Though in this case DDG comes through:
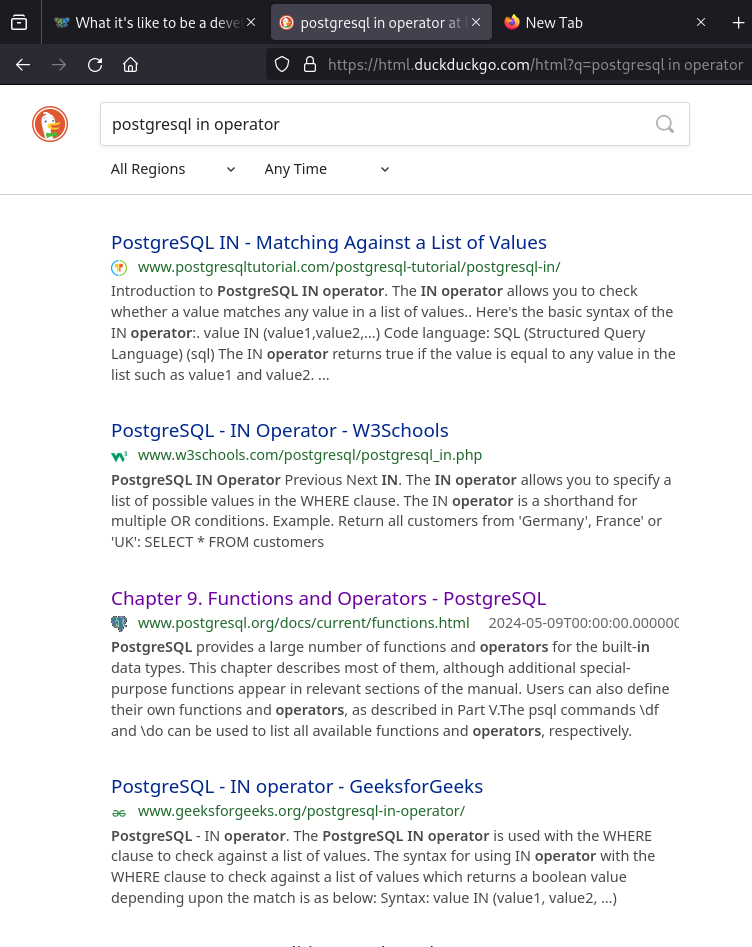
Adding documentation to the search makes the “correct” page soar to the top:

Google is better as a verb than a search engine.
I use “search” as a verb
Haha, nope. The links points to a table of contents after which you are on your own. The right link should point to a specific page instead, but the problem here is that postres docs are poorly optimized for search engines. If you click on the top link from google, you would see there’s a notice that the page is outdated, with a link to a current version, but said link is dead. It’s not an issue I’ve ever experienced with mysql docs for example.
And yes, w3schools, despite how terrible it is, is still above the official docs because it is more popular with newbies. I remember a time when I just started, I preferred sites like it, because they were simple and on point, rather than technically correct and comprehensive like the official docs are. If you forgot the feeling, try learning math on wikipedia (assuming you don’t have a math degree).
For the rest I cannot argue. Generated/AI shit is indeed ruining the internet and search engines giving up and joining them isn’t helpful either.
Trying to learn math on Wikipedia is an endless Sisyphean nightmare just trying to understand the first word in an unfamiliar vocabulary.
After which ctrl+f " in" takes you to the correct chapters. I do agree that a direct link would be more helpful.
And for learning postgresql I agree it isn’t very helpful - using their tutorial links, w3schools or something like udemy if you prefer video format is the way to go in that use case.I remember back when you were told to learn to work with the documentation, not memorize it, because you will always have access to it as a reference. Maybe bookmarking reference books/documentation will make a come back as the search engines degrade.
Surely the word ‘in’ would appear countless times out of context on the table of contents.
" in" appears 25 times on the page to be exact, with 16 of those being in the table of contents and 9 being in the text afterwards.
“in” appears 54 times, as you know end up hitting “string” and so on.Had I known that the functions table of contents was as short as it is I would probably have just scrolled.
This is partly why I prefer Firefox’s implementation of the find feature - it allows case-sensitive search while Chrome does not support it.
In desperation you click the link to the old docs, change the version to the latest version and pray you don’t get a 404
Wait until you see the AI generated blog posts being top results…
Hah!
No.
Soon enough the result will be an AI generated “blogpost”, generated by the search engine, in response to your query.
I’m sure all this nonsense waste of energy is exactly what we needed just to stop climate change.
That’s already been happening for about a month now… perhaps only for some users? Often the AI results are straight up lies.
I’ve seen some fucking hilariously wrong AI math.
There has been something similar for years: a page that basically says “Yeah, nah, we don’t have any information for that, but you might be interested in a totally irrelevant something else”, but phrased in a way that gets it high in the results. What’s astonishing is that Google doesn’t punish those pages.
Why would they punish pages that help them serve more ads? There are ads on the search, ads on the useless result, ads when you refine the query.
Yeah, you have a point, but then it’s a bit hypocritical of them to even have criteria for putting pages up in the results.
It makes me sad because Google used to be great. The main feature that made Google great was the click rejection. Basically the search would know when you clicked on a link and didn’t come back to the search results. This action would add weight to that result as “this probably has the information that was being searched for” so it would be nearer to the top later when others made similar queries.
This was their killer feature, it basically crowd sourced the correct information. After a small amount of time, the correct results would kind of float to the top so subsequent searches would put those results near the top to help satisfy queries faster.
Now? They seem to want to give you results that satisfy their partners, and keep you tied to the results page as long as possible. The focus seems to have shifted from being a good search engine with accurate results, to a meme of how to make money.
Never before has this shift been more clear to me than right now, directly in the wake of I/O 2024; an event my friends have taken to calling AI/O. Pretty much every single presentation was about Gemini and AI generated garbage, but this isn’t what made Google’s new direction clear to me. In the last 20-30 minutes of the event it was made perfectly clear what they were doing with I/O. And to drive the point home, every I/O has showcased stuff you can’t use yet, stuff they’re working on, and other cool shit. Some of it cost money, but there was usually some stuff that was just done because it could be done and it would be made available at some point, a nontrivial amount of it was free. At AI/O, the entire focus was on AI, with little to no non-AI stuff in there, at all, then at the end, they kicked everyone in the shorts. Here’s our prices to access this shit. Buy it. As far as I’m concerned AI/O was a gigantic marketing circle jerk to sell their AI.
It seems that Google has entered the final phases of enshittification.
Well internet enshitification is real…
i wonder how much effort would it take to index all official documentation pages & stackoverflow, and push it into one big search engine
What it’s like to use Google in 2024
Me: “How do I write my own Rawinput handler?”
Search results: “Here’s how you setup Rawinput in this competitive FPS, and look how it reduces input latency by a single milisecond! After 2-3 pages of AI generated SEO garbage full of misinformation, you might find something else besides of the official MS docs.”
Me: “Okay, this is not working, maybe I should look for some another preexisting SDL alternative, maybe at least one of them isn’t an even bigger dumpster fire than SDL itself.”
Search results: “Duuuude, have you heard of this game making tool, called Gamemaker? It doesn’t need coding, and it’s totally the same thing, because some people mistakingly called SDL a game engine, and now my AI hallucinates it as such. If you’re up to a bigger challenge, then there’s always Godot, or DirectX, which my AI also hallucinates being a game engine!”
Wait, Godot isn’t a game engine? I always thought it was one.
It is but DirectX ain’t




{kind=link}