There’s not a lot of data to work with, and the kind of test used to determine significance is not the same across the board, but in this case you can do an analysis of variance. Start with a null hypothesis that the happiness level between distros are insignificant, and the alternative hypothesis is that they’re not. Here are the assumptions we have to make:
An alpha value of 0.05. This is somewhat arbitrary, but 5% is the go-to threshold for statistical significance.
A reasonable sample size of users tested for happiness, we’ll go with 100 for each distro.
A standard deviation between users in distro groups. This is really hard to know without seeing more data, but as long as the sample size was large enough and in a normal distribution, we can reasonably assume s = 0.5 for this.
We can start with the total mean, this is pretty simple:
This makes a total sum of squares of 0.471. With our sample size of 100, this makes for a sum of squares between groups of 47.1. The degrees of freedom for between groups is one less than the number of groups (df1 = 10).
The sum of squares within groups is where it gets tricky, but using our assumptions, it would be:
number of groups * (sample size - 1) * (standard deviation)^2
Which calculates as:
11 * (100 - 1) * (0.5)^2 = 272.25
The degrees of freedom for this would be the number of groups subtracted from the sum of sample sizes for every group (df2 = 1089)
Now we can calculate the mean squares, which is generally the quotient of the sum of squares and the degrees of freedom:
# MS (between)47.1 / 10 = 4.71// Doesn't end up making a difference, but just for clarity# MS (within)272.25 / 1089 = 0.25
Now the F-statistic value is determined as the quotient between these:
F = 4.71 / 0.25 = 18.84
To not bog this down even further, we can use an F-distribution table with the following calculated values:
df1 = 10
df2 = 1089
F = 18.84
alpha = 0.05
According to the linked table, the F-critical value is between 1.9105 and 1.8307. The calculated F-statistic value is higher than the critical value, which is our indication to reject the null hypothesis and conclude that there is a statistical significance between these values.
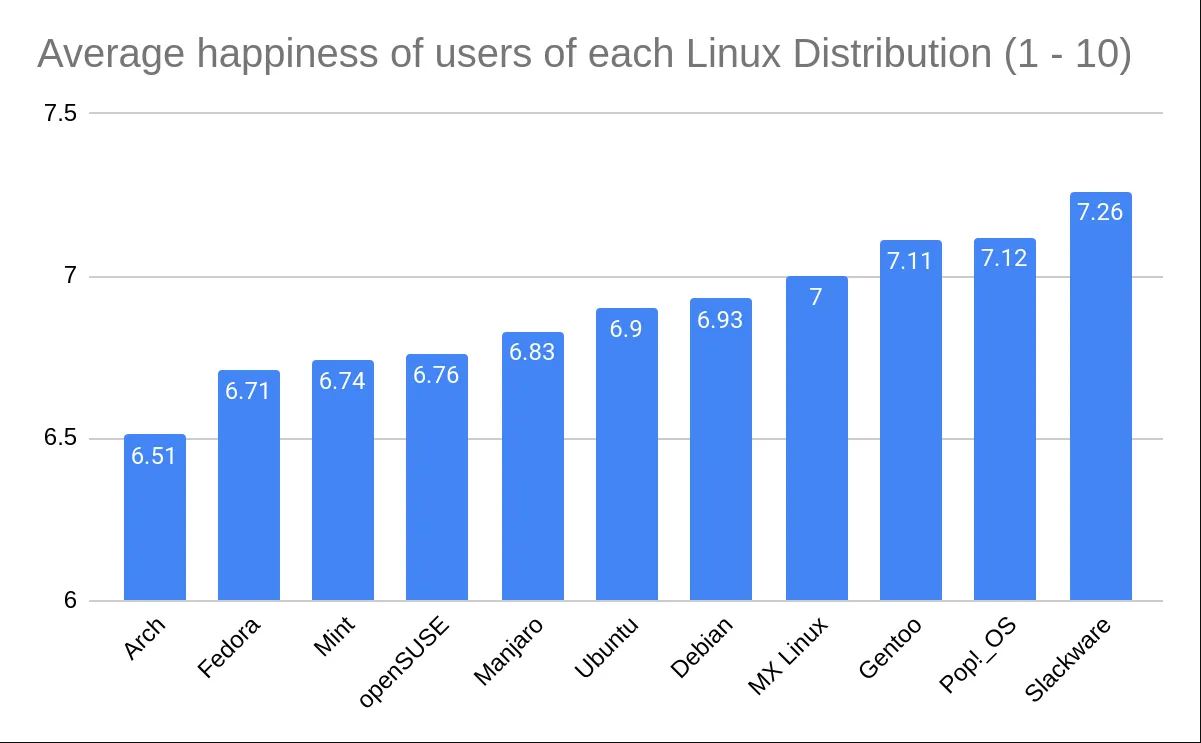
However, again you can see above just how many assumptions we had to make, that the distribution of the data within each group was great in number and normally varied. There’s just not enough data to really be sure of any of what I just did above, so the only thing we have to rely on is the representation of the data we do have. Regardless of the intentions of whoever created this graph, the graph itself is in fact misrepresent the data by excluding the commonality between groups to affect our perception of scale. There’s a clip I made of a great example of this:
There’s a pile of reasons this graph is terrible, awful, no good. However, it’s that scale of the y-axis I want to focus on.
This is an egregious example of this kind of statistical manipulation for the point of demonstration. In another comment I ended up recreating this bar graph with a more proper scale, which has a lower bound of 0 as it should. It’s suggested that these are values out of 10, so that should be the upper bound as well. That results in something that looks like this:
In fact, if you wanted you could go the other way and manipulate data in favor of making something look more insignificant by choosing a ridiculously high upper bound, like this:
But using the proper scale, it’s still quite difficult to tell. If these numbers were something like average reviews of products, it would be easy in that perspective to imagine these as insignificant, like people are mostly just rating 7/10 across the board. However, it’s the fact that these are Linux users that makes you imagine that the threshold for the differences are much lower, because there just aren’t that many Linux users, and opinions wildly vary between them. This also calls into question how that data was collected, which would require knowing how the question was asked, and how users were polled or tested to eliminate the possibility of confounding variables. At the end of the day I just really could not tell visually if it’s significant or not, but that graph is not a helpful way to represent it. In fact, I think Excel might be to blame for this kind of mistake happening more commonly, when I created the graph it defaulted the lower bound to 6. I hope this was helpful, it took me way too much time to write 😂
Oh sport, and I thought I was the one beating on a dead horse here. I understand why people claim to take issue with the Y-axis range. I am just saying chart makers can zoom in to make a point, and it is not automatically misleading. That is all. Anyway, thanks for writing this. Looks like a lot of effort, and some of it will make sense in my stats coursework, thanks!

{kind=link}
There’s not a lot of data to work with, and the kind of test used to determine significance is not the same across the board, but in this case you can do an analysis of variance. Start with a null hypothesis that the happiness level between distros are insignificant, and the alternative hypothesis is that they’re not. Here are the assumptions we have to make:
We can start with the total mean, this is pretty simple:
Now we need the total sum of squares, the squared differences between each individual value and the overall mean:
Arch: (6.51 - 6.897)^2 = 0.150 Fedora: (6.71 - 6.897)^2 = 0.035 Mint: (6.74 - 6.897)^2 = 0.025 openSUSE: (6.76 - 6.897)^2 = 0.019 Manjaro: (6.83 - 6.897)^2 = 0.005 Ubuntu: (6.9 - 6.897)^2 = 0.00001 Debian: (6.93 - 6.897)^2 = 0.001 MX Linux: (7 - 6.897)^2 = 0.011 Gentoo: (7.11 - 6.897)^2 = 0.045 Pop!_OS: (7.12 - 6.897)^2 = 0.050 Slackware: (7.26 - 6.897)^2 = 0.132This makes a total sum of squares of 0.471. With our sample size of 100, this makes for a sum of squares between groups of 47.1. The degrees of freedom for between groups is one less than the number of groups (
df1 = 10).The sum of squares within groups is where it gets tricky, but using our assumptions, it would be:
number of groups * (sample size - 1) * (standard deviation)^2Which calculates as:
The degrees of freedom for this would be the number of groups subtracted from the sum of sample sizes for every group (
df2 = 1089)Now we can calculate the mean squares, which is generally the quotient of the sum of squares and the degrees of freedom:
# MS (between) 47.1 / 10 = 4.71 // Doesn't end up making a difference, but just for clarity # MS (within) 272.25 / 1089 = 0.25Now the F-statistic value is determined as the quotient between these:
F = 4.71 / 0.25 = 18.84To not bog this down even further, we can use an F-distribution table with the following calculated values:
According to the linked table, the F-critical value is between 1.9105 and 1.8307. The calculated F-statistic value is higher than the critical value, which is our indication to reject the null hypothesis and conclude that there is a statistical significance between these values.
However, again you can see above just how many assumptions we had to make, that the distribution of the data within each group was great in number and normally varied. There’s just not enough data to really be sure of any of what I just did above, so the only thing we have to rely on is the representation of the data we do have. Regardless of the intentions of whoever created this graph, the graph itself is in fact misrepresent the data by excluding the commonality between groups to affect our perception of scale. There’s a clip I made of a great example of this:
There’s a pile of reasons this graph is terrible, awful, no good. However, it’s that scale of the y-axis I want to focus on.
This is an egregious example of this kind of statistical manipulation for the point of demonstration. In another comment I ended up recreating this bar graph with a more proper scale, which has a lower bound of 0 as it should. It’s suggested that these are values out of 10, so that should be the upper bound as well. That results in something that looks like this:
In fact, if you wanted you could go the other way and manipulate data in favor of making something look more insignificant by choosing a ridiculously high upper bound, like this:
But using the proper scale, it’s still quite difficult to tell. If these numbers were something like average reviews of products, it would be easy in that perspective to imagine these as insignificant, like people are mostly just rating 7/10 across the board. However, it’s the fact that these are Linux users that makes you imagine that the threshold for the differences are much lower, because there just aren’t that many Linux users, and opinions wildly vary between them. This also calls into question how that data was collected, which would require knowing how the question was asked, and how users were polled or tested to eliminate the possibility of confounding variables. At the end of the day I just really could not tell visually if it’s significant or not, but that graph is not a helpful way to represent it. In fact, I think Excel might be to blame for this kind of mistake happening more commonly, when I created the graph it defaulted the lower bound to 6. I hope this was helpful, it took me way too much time to write 😂
Oh sport, and I thought I was the one beating on a dead horse here. I understand why people claim to take issue with the Y-axis range. I am just saying chart makers can zoom in to make a point, and it is not automatically misleading. That is all. Anyway, thanks for writing this. Looks like a lot of effort, and some of it will make sense in my stats coursework, thanks!