
All in all pretty decent sorry I attached a 35 min video but didn’t wanna link to twitter and wanted to comment on this…pretty cool tho not a huge fan of mark but I prefer this over what the rest are doing…

The open source AI model that you can fine-tune, distill and deploy anywhere. It is available in 8B, 70B and 405B versions.
Benchmarks
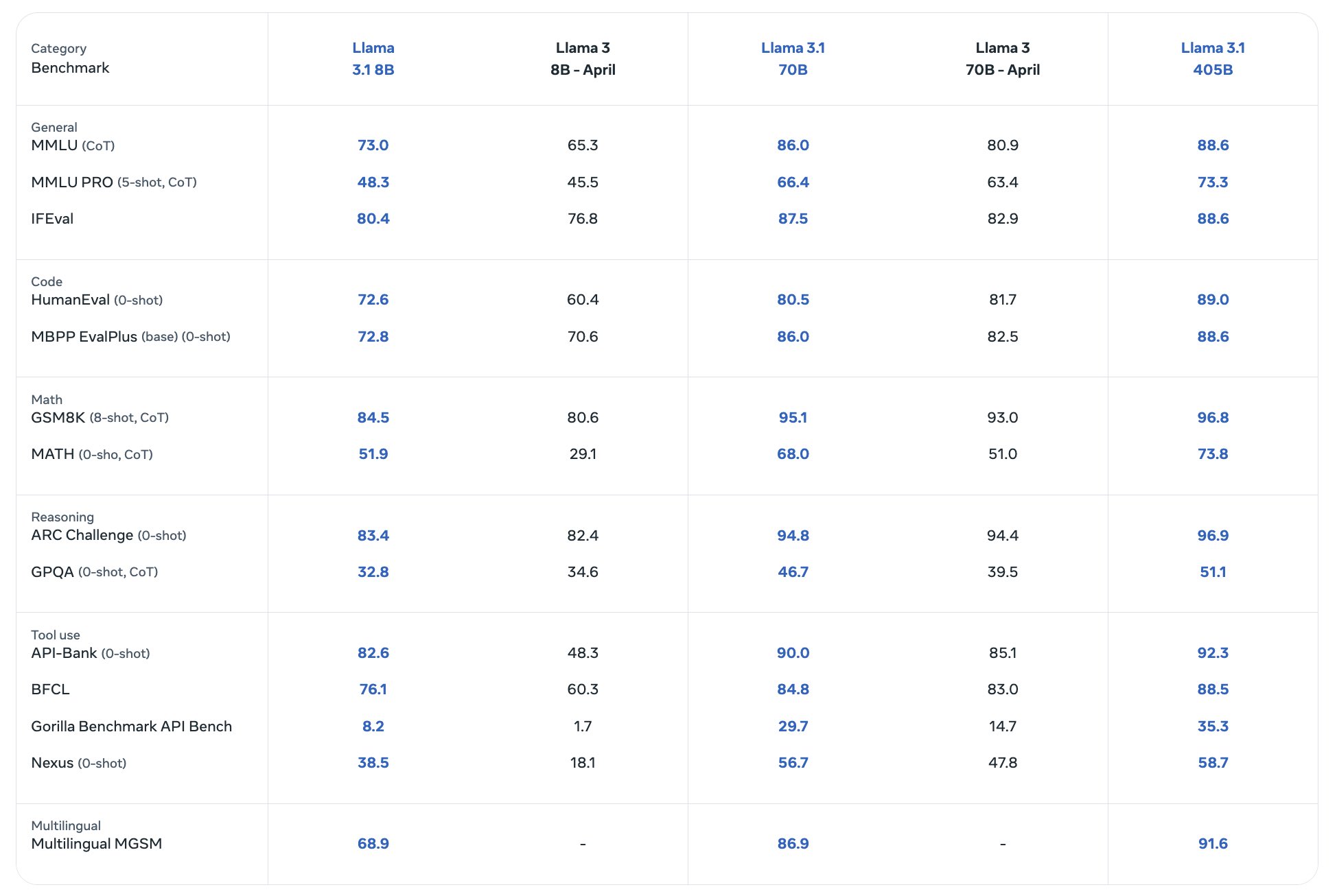
Pretty sure a good chunk of people are actually running 70B models tho
There are ways to bring the models down in size at the cost of accuracy and I believe you can trade off performance to split them across the GPU and the CPU.
Honestly, the times I’ve tried the biggest things out there out of curiosity it was a fun experiment but not a practical application, unless you are in urgent need of a weirdly taciturn space heater for some reason.
Yeah, I prefer to use EXL2 models. GGUF models split across GPU and CPU are slow af, I tried that too. But I’ve seen mutliple people on Reddit claim that they run 70B models on cards like 4090s.
Yeah, the smaller alternatives start at 14 GB, so they do fit in the 24 GB of the 4090, but I think that’s all heavily quantized, plus it still runs like ass.
Whatever, this is all just hobbyist curiosity stuff. My experience is that running these raw locally is not very useful in any case. People underestimate how heavy the commercial options are, how much additional work goes into them beyond the model, or both.
The low quant versions of a 70B model are still way better than a high quant version of an 8B model tho. But yeah, performance might be ass, I don’t have anything like a 4090, so I couldn’t tell you. The main thing I do with these locally run models is use it for SillyTavern, which lets you kinda do roleplay with fictional characters. That’s kinda fun sometimes. But I don’t really use it much besides that either. Just testing how well different models perform and what I can run on my GPU is kinda fun in itself too tho.
For sure, it’s a bit of technical curiosity and an opportunity for tinkering.
And given the absolute flood of misinformation around and about machine learning and “AI”, I also find it to be a hygiene thing to be able to identify bullshit on both the corporate camp and the terminally online criticism. Because man, do people say a lot of wild stuff that doesn’t make sense about this subject. Looking under the hood seems like a good thing to do.