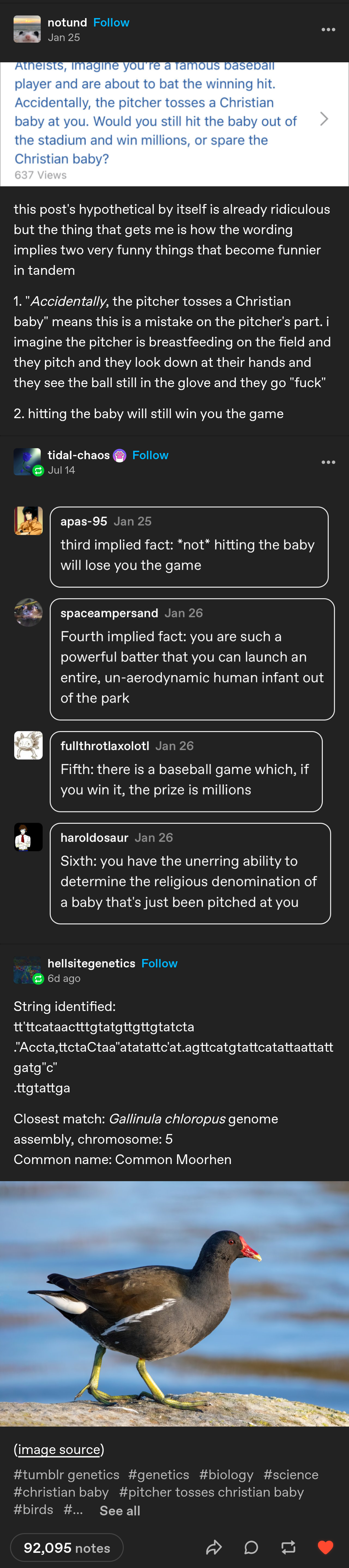
As per my other post, this person isn’t doing any of that.
But, since you asked for papers on generic matching algorithms, I found this during the silent conniption fit you sent me into after suggesting that some random tumblr user plugged a tumblr bot directly into a state of the art genomics db.


{kind=link}
As per my other post, this person isn’t doing any of that.
But, since you asked for papers on generic matching algorithms, I found this during the silent conniption fit you sent me into after suggesting that some random tumblr user plugged a tumblr bot directly into a state of the art genomics db.
https://link.springer.com/article/10.1007/s11227-022-04673-3
Please note that while, yes, they ran this test on a standard office computer, they were only searching against 12 million characters.
A single terabyte of characters would be more like 1 trillion characters. A pebibyte would be more like 1 quintillion.
… much, much, much longer processing times.